

A vast majority of financial institutions run into the same problem every day: how to handle piles of papers and gigabytes of exchanged documents. Such data is often left unorganized and unstructured. In order to make use of it, one has to classify it. Data classification makes it easier to locate, retrieve, and use data. It becomes crucial when it comes to compliance, data security, legal discovery, and risk management.
Transaction Categorization: Business Case
What is Data Mining, and Why Does It Matter?
Data mining (a subcategory of AI) is all about analyzing data from various angles and extracting useful information for future actions. It helps store, process, and analyze massive amounts of raw data. The following technology utilizes machine learning, pattern recognition, statistics, visualization, and databases to extract and process data. Data mining is said to be the most powerful tool for business optimization.
Financial data analysis is widely used in most financial and banking institutes for accurate analysis of consumer data to reduce manual errors, find defaulters, for fast processing, classify the customers, and reduce the loss of the financial institutions.
Data mining is widely used in the banking sector to tackle the following problems:
- Credit card fraud detection
- Loans and mortgage decisions
- Marketing
- Loyalty programs
- Customer retention
Introduction to data mining to find out how to use data mining for your business.
What is Data Classification?
Data classification is all about organizing crucial business information. It’s a set of processes aimed at managing data by categories and tags. Only well-categorized data can be more efficiently used across the company for risk management, legal discovery, and compliance processes.
Organized data allows enterprises to identify the business value of unsorted data, make use of important information, and make well-informed decisions. Information is divided into predefined groups sharing a common risk and properly secured. Successful data classification applies security controls to a set of data. It also helps companies meet regulatory requirements – such as those within the GDPR in Europe or FINRA in the US.
Before Machine Learning, data classification was a user-driven process, but nowadays, enterprises can automate data classification processes. But with automated data classification tools, it becomes much easier to categorize any data. First, you need to determine the categories and criteria for data classification, define and understand its objectives, redefine the roles and responsibilities of employees, and implement required security standards.
Benefits of Data Classification for the Financial Sector
Proper data classification helps improve both regulatory compliance and data security. Here’s how your company may benefit from implementing data classification tools:
- Better manage the high volumes of sensitive information
Thanks to sophisticated technologies, users can quickly process and classify large amounts of data.
- Organize and track crucial data
Nearly 80% of companies do no know how and where they store their sensitive data. With a proper data classification system, you get easily accessible but well-protected data from leaks.
- Detect abnormal activity
Neural networks are well-trained to detect any abnormalities in data classification.
- Optimal use of resources while reducing useless costs
Having determined the importance of different data types, you can focus on data that should be protected at all costs without wasting your resources on less critical or non-critical data.
- Error-free data classification
Machine learning technologies help process large amounts of financial data and classify it while minimizing human errors.
- Make it easier to comply with regulatory mandates
There are particular frameworks like SEC, FINRA, and GDPR that you need to follow while dealing with sensitive data, such as personally identifiable information and payment data. The following data type should be classified as confidential or restricted. Otherwise, some financial penalties may incur. In such a way, you protect sensitive data from being disclosed without authorization or transmitted through unprotected or unencrypted channels.
Classification in data mining is a cumbersome and quite complex process. But when implemented properly, it can become a crucial framework to store, transmit, and retrieve data for employees and any third parties.
Why It’s Better to Classify Your Data
A properly planned data classification system makes crucial data easy to trick and manipulate. That’s the primary reason why you should organize your data. The most common goals include but aren’t limited to the following according to Data Classification for Cloud Readiness by Microsoft:
- Security. A classification system should value confidentiality above other attributes and focus on security measures, including encryption and user permissions, to protect sensitive information. Security and confidentiality are of particular importance when it comes to financial records.
- Data integrity. Your system should ensure the accuracy and consistency of data over its entire life cycle.
- Data availability. All the data should always be accessible when and where needed within the company’s IT infrastructure. The reality is that when your data isn’t accessible when needed, it’s worthless.

Data classification ensures that a company follows all internal and external (including company, local, and federal) guidelines for data handling and maximizes data security.
Types of Data Levels and Classification
Data classification is quite a complex process involving a multitude of labels and tags to denote its type, confidentiality, and integrity. Data security is often classified according to its levels of importance and confidentiality. Hence, data categories are linked with the security measures required to protect the data from leaks.
There are dozens of ways to categorize your data, but the most common classification levels are stated as follows – public, private or internal, confidential, and restricted.

Main Types of Data Classification
- Data classification system based on content scans the data and looks for sensitive information;
- Data classification system based on context considers apps, locations, and creators while classifying sensitive information;
- Data classification system based on users analyzes users’ interactions with documents to tag sensitive information.
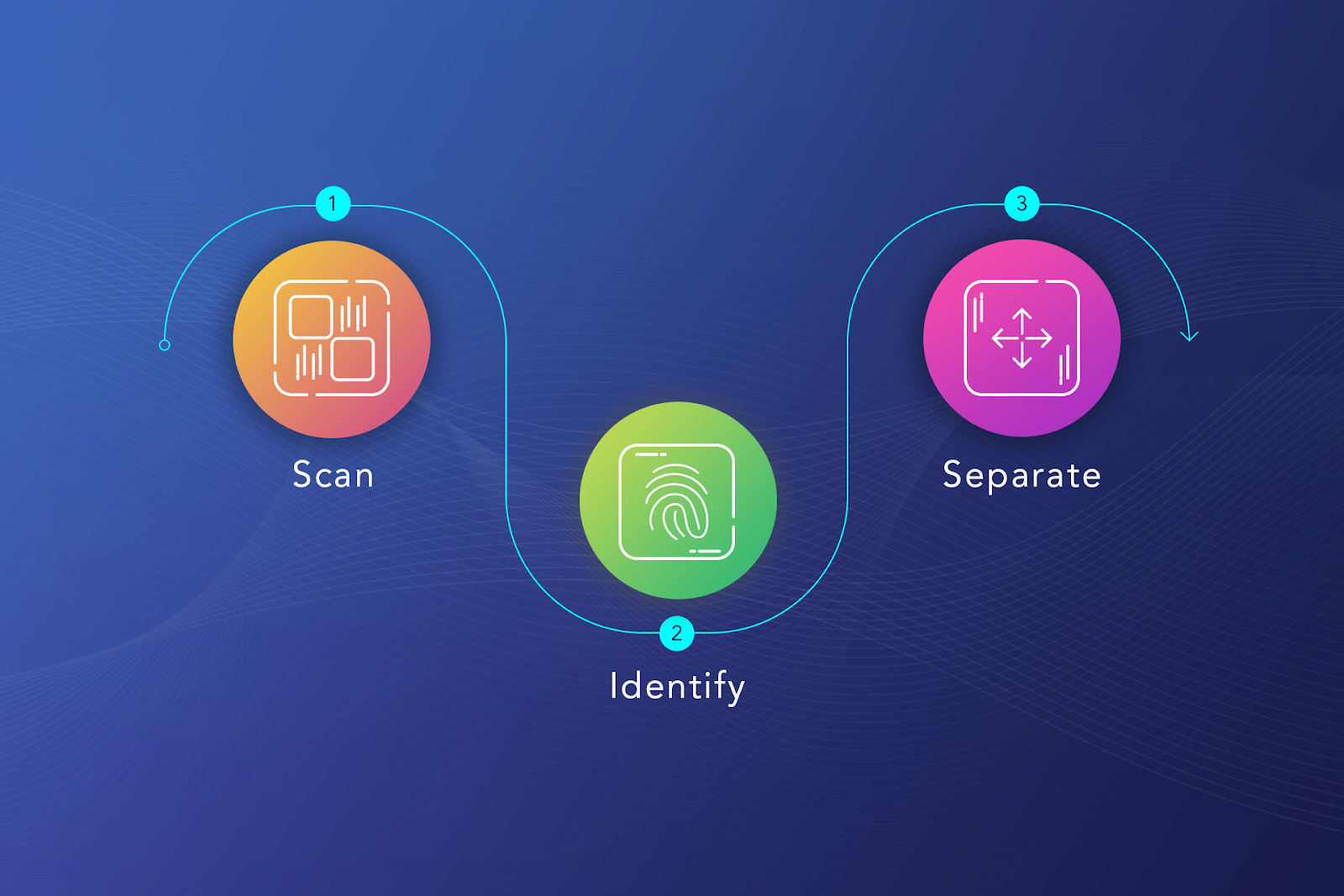
3 Steps to Effective Data Classification
In most cases, not all data needs to be organized and stored; in some cases, it’s even better to delete it. And the data you want to be classified will go through a 3-step process:
- Scan. Take your entire database and turn it into digital to start classifying and organizing your data.
- Identify. Define data types, label them, and make the information searchable and sortable.
- Separate. When the data is categorized with a system, it can be easily separated by predefined categories.
Summing Up
Data classification helps financial and banking institutes secure their sensitive information but still makes it easy to retrieve it. Also, it reduces the likability of unorganized crucial information becoming vulnerable to hackers, and it helps cut down useless costs for data storage since storing large amounts of unstructured information costs a pretty penny.
And with a Data Classification Solution, you’ll be able to tag and classify data as well as detect any abnormal activity in a few clicks. Using AI and ML technologies, you’ll reduce the chances of human errors and triple your productivity.


